
Chinese researchers develop cheaper way to train AI without expensive updates
New method costs $18 instead of $10,000 while improving AI performance on math and search tasks.

Researchers from Tencent Youtu Lab announced a breakthrough on October 9, 2025, that makes training AI models dramatically cheaper. The technique, called Training-Free GRPO, improves how AI agents work without the expensive computer processing that traditional methods require.
Most AI companies spend thousands of dollars updating their models to work better at specific tasks. This process, called fine-tuning, changes the model's internal settings through expensive computing power. The new approach skips these updates entirely.
Subscribe PPC Land newsletter ✉️ for similar stories like this one. Receive the news every day in your inbox. Free of ads. 10 USD per year.
Instead of changing the AI model itself, the researchers teach it by giving it written instructions based on experience. Think of it like giving someone a cheat sheet instead of sending them back to school.
The technique works by running the AI through problems multiple times, then comparing which approaches worked best. The AI learns from these comparisons and creates a set of guidelines for handling similar problems in the future.
Machine learning automation continues transforming how companies manage advertising campaigns, with platforms balancing efficiency against advertiser control.
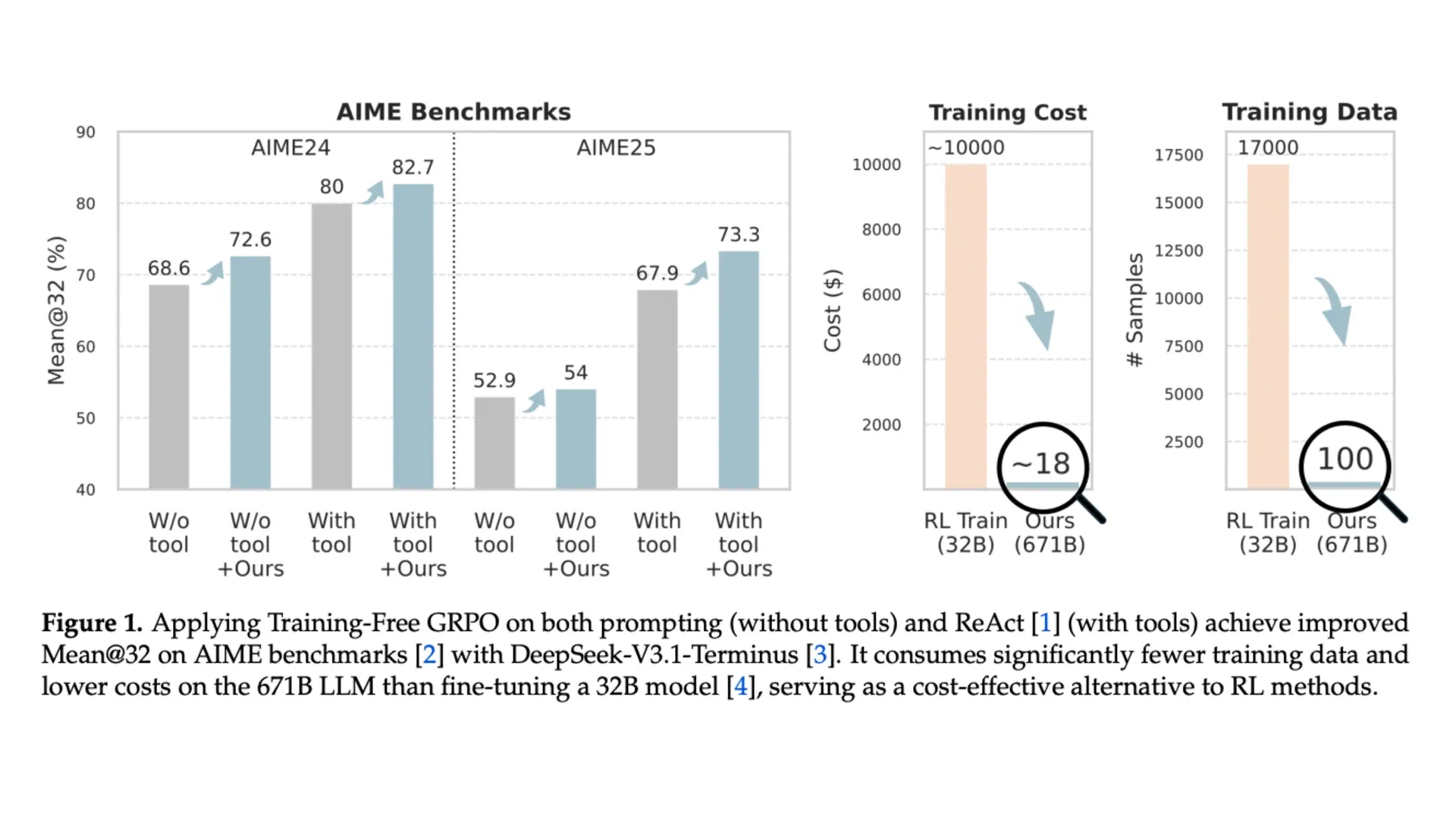
Testing showed impressive results. On difficult math problems called AIME benchmarks, the technique achieved 82.7% accuracy on 2024 tests and 73.3% on 2025 tests when combined with a code interpreter. This beat the baseline performance by 2.7% and 5.4% respectively.
The cost difference proves striking. The researchers spent approximately $18 and used only 100 training examples. Traditional methods like ReTool require thousands of examples and cost more than $10,000 to train smaller AI models.
Web searching tasks showed similar improvements. On the WebWalkerQA benchmark, the method achieved 67.8% accuracy, a 4.6% improvement over standard approaches. The training consumed 38 million input tokens and 6.6 million output tokens over three training steps completed in six hours.
AI-powered optimization tools have become increasingly important as marketing teams face pressure to deliver results with fewer resources.
A key advantage emerges when switching between different types of tasks. Traditional fine-tuned models perform poorly when moved to different domains. A model trained for math drops from 67% accuracy on math problems to just 18% on web searches. Another model optimized for web searching similarly struggles with math.
The new method maintains strong performance across both areas by simply swapping instruction sets. This flexibility matters because companies typically need AI that handles multiple tasks rather than separate specialized models for each job.
The researchers tested their approach on DeepSeek-V3.1-Terminus, a large AI model with 671 billion parameters. They also tried smaller models like Qwen3-32B and Qwen2.5-72B-Instruct, finding consistent improvements across different sizes.
During testing, the AI learned to use tools more efficiently. The average number of tool calls decreased both during training and when solving new problems. This suggests the method teaches the AI not just what to do, but also how to work smarter.
The technique even works without knowing the correct answers during training. Testing without ground truth still achieved 80.7% on AIME24 and 68.9% on AIME25. The AI relies on comparing multiple attempts and identifying patterns to figure out better approaches.
Buy ads on PPC Land. PPC Land has standard and native ad formats via major DSPs and ad platforms like Google Ads. Via an auction CPM, you can reach industry professionals.
Agentic AI systems are reshaping how organizations approach marketing automation, with McKinsey identifying these technologies as frontier developments driving industry transformation.
Smaller tests confirmed that comparing multiple attempts matters. When researchers set the comparison group size to just one attempt instead of five, performance dropped significantly. This validates that the AI benefits from seeing different approaches to the same problem.
Real-world deployment costs favor this approach for many businesses. Traditional trained models require dedicated servers running continuously. A typical setup costs $0.005 per problem but assumes constant server availability, making it inefficient for sporadic use.
The new method operates on a pay-as-you-go basis through API calls. Each problem costs about $0.02 but requires no dedicated infrastructure. For businesses with irregular or unpredictable usage patterns, this proves more economical than maintaining servers that sit idle between requests.
Marketing platforms increasingly integrate AI capabilities to help teams interact with data through natural language rather than technical queries.
The research addresses a persistent problem in AI development. Most companies can only afford to fine-tune smaller models due to computational costs. These smaller models deliver worse results than simply using larger general-purpose models through API calls.
This creates an awkward situation where the affordable option performs poorly in specialized tasks, while the better-performing option lacks specialized knowledge. The new method resolves this dilemma by enhancing large general-purpose models through inexpensive instruction sets.
The technique learned 48 different pieces of experience during math training. These ranged from validating that solutions fall within proper boundaries to understanding when compass directions like "southwest" and "southeast" form right angles.
For web searching, the AI learned to prioritize official sources over third-party summaries, refine search terms based on formal titles, and verify numerical claims at their authoritative origins. These learned behaviors directly address common failures in baseline approaches.
The marketing community should pay attention because this technology makes advanced AI capabilities accessible to smaller budgets. Previously, only large companies could afford specialized AI model training. Now, businesses can achieve similar results for less than the cost of dinner for two.
Technical guides for building AI marketing agents emphasize practical implementation steps that avoid common development pitfalls organizations encounter.
The approach also solves the problem of needing multiple specialized models. A company might need AI for customer service, content creation, data analysis, and ad optimization. Training separate models for each task multiplies costs and complexity. Using one flexible model with different instruction sets proves simpler and cheaper.
Looking forward, this technology could democratize AI capabilities across the marketing industry. Smaller agencies and in-house teams gain access to sophisticated AI tools without enterprise-level budgets. The barrier to entry drops from tens of thousands of dollars to hundreds.
Subscribe PPC Land newsletter ✉️ for similar stories like this one. Receive the news every day in your inbox. Free of ads. 10 USD per year.
Timeline
- October 9, 2025: Tencent Youtu Lab publishes Training-Free GRPO research
- September 2025: IAB Europe releases framework for AI publisher compensation
- September 2025: Google introduces text guidelines for AI-powered campaigns
- July 2025: McKinsey analysis reveals AI agents reshaping advertising
- July 2025: Similarweb launches AI search optimization toolkit
- October 2024: Spotify deploys machine learning for user acquisition
Subscribe PPC Land newsletter ✉️ for similar stories like this one. Receive the news every day in your inbox. Free of ads. 10 USD per year.
Summary
Who: Researchers from Tencent Youtu Lab including Yuzheng Cai, Siqi Cai, Yuchen Shi, and Zihan Xu developed the technique.
What: Training-Free GRPO teaches AI models through written experience-based instructions instead of expensive fine-tuning, achieving better performance at dramatically lower costs.
When: Published October 9, 2025, with experiments using 100 training samples completed in six hours at approximately $18 cost compared to traditional methods costing over $10,000.
Where: Tested on AIME mathematical reasoning and WebWalkerQA web searching benchmarks using DeepSeek-V3.1-Terminus and other large language models.
Why: Makes advanced AI capabilities accessible to smaller budgets by eliminating expensive computational requirements while maintaining performance across different task types without needing multiple specialized models.