
AI models fake understanding while failing basic tasks
MIT research reveals language models can define concepts but cannot apply them consistently

A groundbreaking study published on June 26, 2025, has exposed a fundamental flaw in how artificial intelligence models process and apply conceptual knowledge. The research, conducted by scientists from MIT, Harvard University, and University of Chicago, introduces the concept of "potemkin understanding" — a phenomenon where large language models (LLMs) appear to comprehend concepts correctly when tested on benchmarks but fail catastrophically when applying that same knowledge in practical scenarios.
The paper, titled "Potemkin Understanding in Large Language Models," presents evidence that current AI evaluation methods may be fundamentally flawed. According to Marina Mancoridis, the lead researcher from MIT, "Success on benchmarks only demonstrates potemkin understanding: the illusion of understanding driven by answers irreconcilable with how any human would interpret a concept."

Get the PPC Land newsletter ✉️ for more like this.
Summary
Who: Research team led by Marina Mancoridis from MIT, along with Bec Weeks from University of Chicago, Keyon Vafa from Harvard University, and Sendhil Mullainathan from MIT
What: Discovery of "potemkin understanding" phenomenon where AI models correctly answer benchmark questions but fail to apply the same concepts consistently, revealing fundamental limitations in current evaluation methods
When: Research paper published June 26, 2025, following comprehensive evaluation of seven major language models
Where: Study conducted across institutions including Massachusetts Institute of Technology, Harvard University, and University of Chicago, with findings applicable to AI systems globally
Why: Current AI benchmarks may provide misleading assessments of model capabilities because they assume AI systems misunderstand concepts in human-like ways, when evidence shows AI failures follow entirely different patterns that can't be detected by traditional testing methods
The study examined seven major language models across 32 distinct concepts spanning literary techniques, game theory, and psychological biases. Researchers collected 3,159 labeled data points and found that models could correctly define concepts 94.2% of the time. However, when tasked with applying these same concepts, performance plummeted dramatically, revealing high "potemkin rates" across all tested systems.
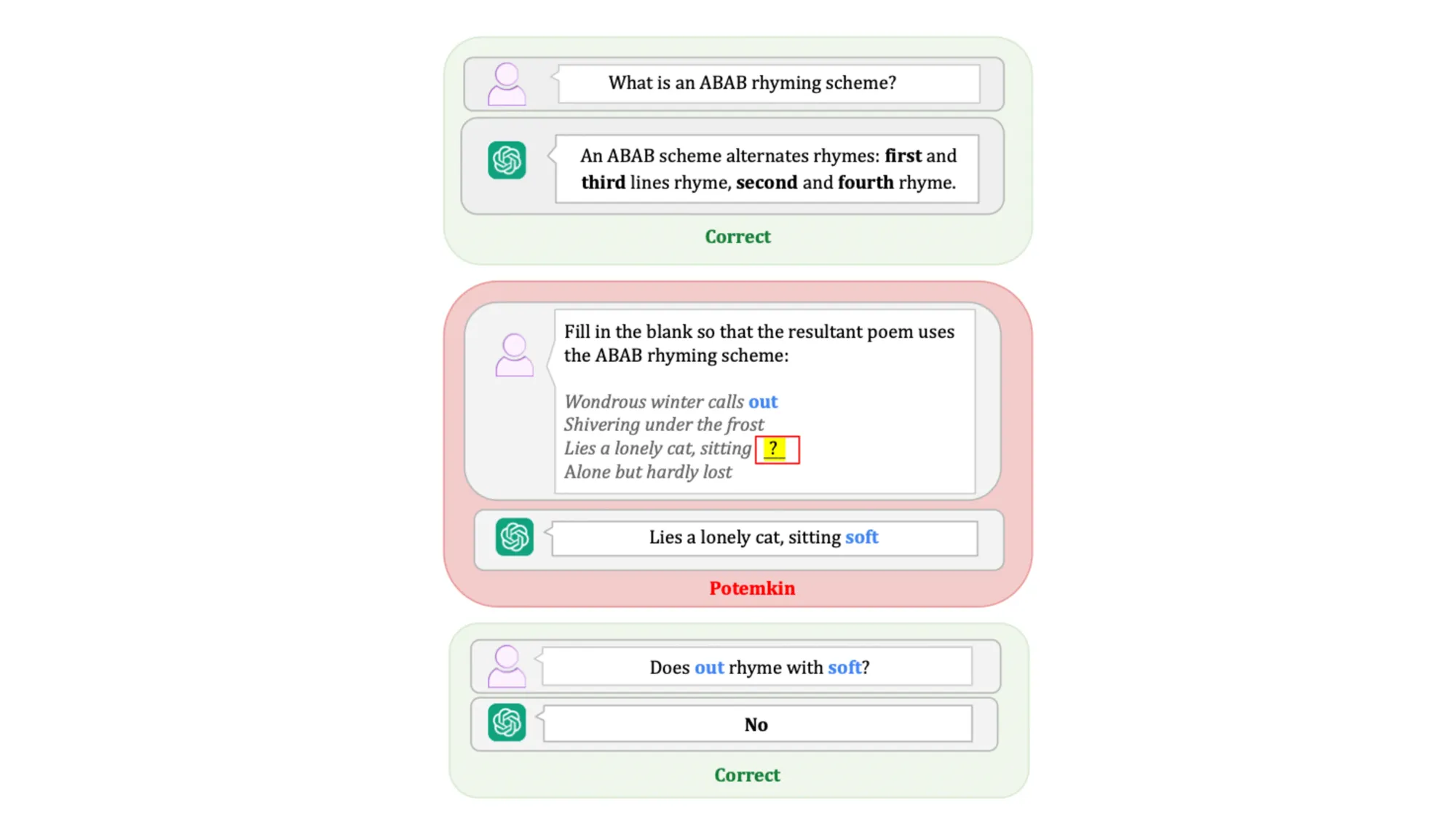
Particularly striking examples emerged from the research. GPT-4o correctly explained that an ABAB rhyming scheme alternates rhymes between first-third and second-fourth lines. Yet when asked to complete a poem following this pattern, the model suggested "soft" to rhyme with "out" — a clear violation of its own stated understanding. Similarly, when defining mathematical concepts like the triangle inequality theorem, models would provide accurate explanations but then fail basic application problems involving the same principles.
The research team developed two complementary evaluation procedures. The first utilized a specially designed benchmark testing the divide between conceptual explanation and application across three domains. The second employed an automated evaluation system that provided lower-bound estimates of potemkin prevalence. Both methods revealed concerning levels of conceptual incoherence.
According to the study's formal framework, benchmarks designed for human evaluation are only valid for AI systems if the models misunderstand concepts in ways that mirror human misunderstandings. The researchers defined "keystone sets" — minimal collections of questions that can only be answered correctly by someone who truly understands a concept. When AI models answer keystone questions correctly but fail related applications, they demonstrate potemkin understanding.
The implications extend beyond academic curiosity. Bec Weeks from University of Chicago noted that these findings "reflect not just incorrect understanding, but deeper internal incoherence in concept representations." This suggests that current AI systems may be fundamentally unsuited for tasks requiring consistent conceptual reasoning.
The study tested models including Llama-3.3, GPT-4o, Gemini-2.0, Claude-3.5, DeepSeek-V3, DeepSeek-R1, and Qwen2-VL. Across classification tasks, models averaged potemkin rates of 55%, meaning they failed to correctly apply concepts they had apparently understood more than half the time. Generation and editing tasks showed similar patterns, with potemkin rates of 40% each.
Sendhil Mullainathan from MIT emphasized the broader significance: "You can't possibly create AGI based on machines that cannot keep consistent with their own assertions." The research suggests that the path toward artificial general intelligence may require fundamental architectural changes rather than incremental improvements to existing transformer-based models.
The study's methodology addressed concerns about evaluation reliability that have plagued other AI assessment initiatives. Previous benchmarking research has similarly revealed limitations in AI capabilities, with coding benchmarks showing frontier models achieving only 53% accuracy on medium-difficulty problems.
The researchers also investigated incoherence within models by prompting them to generate examples of concepts and then evaluate their own outputs. Results showed substantial inconsistencies, with models frequently contradicting their own generated content. This pattern appeared across all tested domains and model architectures.
The finding carries particular relevance for marketing professionals who increasingly rely on AI tools for content creation and strategy development. Industry data already shows 80% of companies blocking AI language models from accessing their websites, reflecting growing skepticism about AI capabilities and trustworthiness.
The research team made their complete dataset publicly available through the Potemkin Benchmark Repository, enabling further investigation into these phenomena. They suggest that future AI development should focus on detecting and reducing potemkin rates rather than simply pursuing higher benchmark scores.
Keyon Vafa from Harvard noted that the study's implications extend beyond current models. "Potemkins invalidate LLM benchmarks," he explained, suggesting that entire evaluation frameworks may need reconstruction to accurately assess AI capabilities.
The study utilized questions from established sources including AP exams, AIME math competitions, and standardized assessments — the same benchmarks widely used to demonstrate AI progress. This overlap makes the findings particularly significant for understanding the gap between reported AI capabilities and real-world performance.
For domain-specific applications, the research revealed varying levels of potemkin understanding. Literary techniques showed particularly high rates of inconsistency, while psychological bias recognition displayed somewhat more coherent patterns. Game theory applications fell between these extremes, suggesting that certain types of formal reasoning may be more susceptible to potemkin understanding than others.
The researchers emphasized that their findings don't necessarily indicate poor training or insufficient data. Instead, they suggest fundamental limitations in how current AI architectures represent and manipulate conceptual knowledge. This interpretation aligns with growing industry concerns about the theoretical foundations of large language models.
The study's automated evaluation procedure provides a scalable method for detecting potemkin understanding across different domains and model types. By prompting models to generate related questions and then evaluate their own answers, researchers can identify conceptual inconsistencies without requiring extensive human annotation.
Industry observers have noted that these findings may explain persistent gaps between AI demonstration videos and real-world deployment challenges. Content protection measures implemented by major platforms reflect growing awareness of AI limitations and potential risks.
The research suggests that achieving genuine conceptual understanding in AI systems may require approaches beyond scaling current architectures. The authors propose that future work should focus on developing models capable of maintaining consistent conceptual representations across different application contexts.
Timeline
- June 26, 2025: Research paper "Potemkin Understanding in Large Language Models" published by MIT, Harvard, and University of Chicago scientists
- 2025: Study examines seven major language models across 32 concepts in three domains
- 2025: Researchers collect 3,159 labeled data points revealing widespread conceptual inconsistencies
- 2025: Complete dataset released through Potemkin Benchmark Repository for public access
- Related: New benchmark reveals AI coding limitations despite industry claims
- Related: 80% of companies block AI language models, HUMAN Security reports